Kaikki joukolla vanhoja käsialoja tulkitsemaan
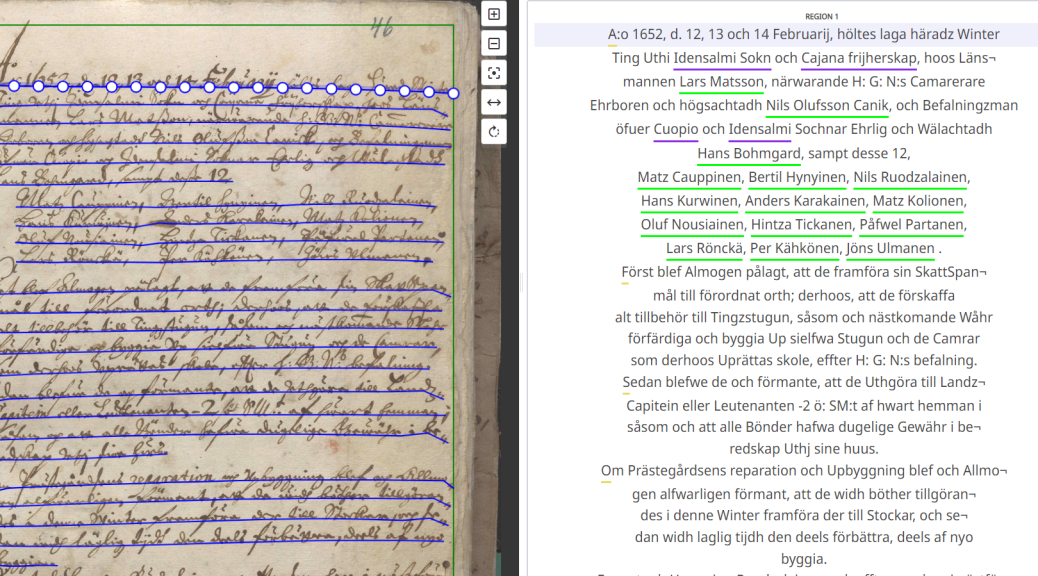
Kyky lukea vanhoja käsialoja on historiantutkijan ja lähitieteiden edustajien perustaito, mikäli tutkimuskohteena on 1900-luvun alku tai sitä vanhemmat vuosisadat. Paleografia on tekstuaalitieteiden tutkimusala, joka tutkii kirjoitusmerkkien, kirjoitusvälineiden ja ennen muuta kirjoittamisen kehitystä. Ymmärrys kirjainten ja käsialojen kehitysvaiheista auttaa myös niiden ajoittamisessa ja tulkitsemisessa. Esimerkiksi varhaismodernin ajan Ruotsissa vallitseva käsialatyyli oli saksalainen eli uusgoottilainen tyyli, jonka yleisilme vaihteli vuosisadoittain. Se poikkesi läntisen ja eteläisen Euroopan latinalaisesta kirjoitustyylistä, joka tuli Suomessa vallitsevaksi, ja sittemmin nykylukijalle tutuksi, tyyliksi vasta 1800-luvun aikana.
Perusopintojen aikaan tutustuin vanhojen käsialojen tulkinnan perusteisiin muun muassa 1600-luvun tuomiokirjoja sekä 1800-luvun kirkonkirjoja sisältäneiden harjoitusten myötä. Tehtävät olivat varsin mekaanisia, mutta viime kädessä vanhojen aineistojen tulkinnan opetteleminen vaatii kärsivällisyyttä ja istumalihaksia. Kandidaatintutkielmaa varten sain tulkittua muutamia oikeudenkäyntipöytäkirjojen tapauksia, graduun useita kymmeniä. Tuolloin oma työskentely tuntui kovin hitaalta – mitä se varmasti olikin – mutta toisaalta taidot olivat muutaman vuoden tasaisen uurastamisen myötä huomattavat verrattuna alkupisteeseen.
Sittemmin olen ollut kehittämässä vanhojen käsialojen opetusta niin Jyväskylän yliopiston, avoimen yliopiston kuin kansalaisopistojen tunneilla. Lisäksi olen muutamana vuotena pyörittänyt Agricola – Suomen humanistiverkon kautta valtakunnallista paleografia-verkkokurssia. Vanhojen käsialojen tulkitsemisen opetuksessa olen korostanut erityisesti sitä, että perustaidot ja ymmärrys niiden itsenäisen kehittämisen potentiaalista on riittävää. Osa itsekriittisistä opiskelijoista on kurssien päätyttyä hieman harmissaan, kun eivät saa laajojen harjoitustehtävien tulkintojaan sataprosenttisella kirjaintarkkuudella oikein. Yritänkin painottaa, että aihepiiri on niin haastava, että jokainen voi olla tyytyväinen, kunhan saa aineistoista tulkittua suurimman osan ja eritoten ymmärrettyä olennaisen. Yhden kurssin jälkeen kukaan ei ole täydellisen valmis uuden ajan alun lähteiden tulkitsija, mutta ilokseni useimmat opiskelijat ovat siinä hämmästyttävän taitavia, taidollisen loppusilauksen syntyessä vuosien harjaantumisen myötä.
Kursseilla aloitan tehtävät helpommista 1800- ja 1900-luvun taitteen aineistoista. Tehtävien edetessä varhaisempiin vuosisatoihin olen lopulta viimeisinä opetuskertoina luetuttanut 1500-luvun käsialaa. Siihen voi opettajan kanssa sukeltaa yhdessä turvallisesti ja vaikka kaikki Kustaa Vaasan ajan aineistot eivät parin kokeilukerran jälkeen selkeytyisi täydellisesti, ovat opiskelijat syväsukelluksen jälkeen huomanneet, kuinka helppoa on palata kurssin alussa mahdottomilta tuntuneisiin 1700- ja 1800-luvun aineistoihin. Koen tärkeänä, että jokainen opiskelija saisi onnistumisen kokemuksia. Tässä on kuitenkin suuria eroja: osalle 1600-luvun tuomiokirja voi olla luontaisesti helpompaa luettavaa kuin 1800-luvun kirkonkirjat. Siksi harjoituksia on hyvä olla eri vuosisadoilta eri käsien kirjoittamina erilaisista aineistotyypeistä.
Kuten muillakin kursseilla, on paleografian opetuksessa kyse teoreettisen perustan sisäistämisestä ja rajatusta määrästä harjoitteita. Todelliseksi ammattilaiseksi tullaan vasta toistojen myötä, esimerkiksi pro gradu -tutkielmaa tai väitöskirjaa työstettäessä. Kohtalaisen kokeneena vanhojen aineistojen lukijana opin itsekin yhä uutta. Lähes jokaisella tuomiokirja-aukeamalla on ilmaus tai pari, jotka aiheuttavat tulkintavaikeuksia joko käsialan epäselvyyden takia tai jos sanat eivät ole merkitykseltään entuudestaan tuttuja. Oikeastaan tutkijan arjessa näiden pähkinöiden selvittäminen on virkistävää, vaikka välillä tutkimuksen kokonaisuuden kannalta toissijaisten sanojen tulkinta imee turhankin aikaa vievästi mukaansa. Mutta kyse on nimenomaan kumuloituvasta oppimisesta, tietotaitoa ja samalla ymmärrystä tutkimuskohteesta karttuu huomaamatta lisää, kun ottaa pähkinöitä purtavakseen.

Tulevina vuosina opiskelijoiden valmiuksia lukea uuden ajan alun ja keskiajan käsinkirjoitettuja lähteitä tulee haastamaan sekin, että kaunokirjoituksen pakollinen opetus loppui peruskouluissa vuonna 2016 – vaikka sitä yhä voi osassa kouluja opetella valinnaisaineena. Käsialakiemuroiden lisäksi varhaismodernin Suomen ja Ruotsin lähteissä haasteen asettaa ruotsin kieli, vanhahtava sellainen. Osa opiskelijoista lyö jo pelkän ruotsin takia neliraajajarrutuksen päälle: ”ei pysty”. Tätä kovin reaktiivista hidastetta olen opetuksessa purkanut siten, että ensiksi harjoitellaan tulkitsemaan teksteistä erisnimiä, jotka eivät vaadi kielipäätä. Tämän jälkeen on edetty etsimään teksteistä ruotsin kielen yleisimpiä sanoja, kuten är, efter, det, men, april, han/hon, som, jotka varmasti jokainen tuntee. Tässä vaiheessa yleensä jo huomataan, että erisnimien ja perussanaston auettua puuttuu virkkeistä enää vain muutamia erityisempiä sanoja, jotka nekin lopulta avautuvat helpommista sanoista löytyviin kirjaimiin vertaamalla. Ylipäätään vanhojen asiakirjojen sanasto on suppeaa: kuten kirjaimet koukeroineen, alkaa sanastokin hyvin pian toistaa itseään. Tavoitteena onkin siirtyä heti kun mahdollista tarkastelemaan yksittäisten kirjainten sijaan sanoja ja niiden muodostamia loogisia kokonaisuuksia.
Olen yksi Vanhojen käsialojen lukuoppaan (Gaudeamus 2021/2023) toimittajista. Teos sisältää vinkkejä vanhojen käsialojen tulkintaan harjoitteineen ja painottaa erilaisten aineistojen rakennetta ja sisältöä lähdekriittisesti: vanhan aineiston tulkinta on helpompaa, kun jo etukäteen ymmärtää, mitä lähde todennäköisimmin sisältää. Olenkin huomannut, että mitä enemmän jaksaa nähdä vaivaa sen eteen, että harjoitusaineistot sisältäisivät kontekstiltaan mielenkiintoista juttuja, sitä innostuneempia ja motivoituneempia opiskelijat ovat syventymään ja käyttämään aikaresurssejaan vaikean taidon opettelemiseen. Esimerkiksi tuomiokirjan äärellä jaksaa istua omaa tulkintaa nysväämässä, jos lähtötietona tietää sen sisältävän 1600-luvun ihmiskohtaloita esimerkiksi salavuoteusoikeudenkäynnistä. Omana opiskeluaikanani kirjaimia tulkittiin välillä varsin mekaanisesti kirjainten ja yksittäisten sanojen itsensä takia, ei niinkään mielekkään tapauksen ja sen kontekstin avaamiseksi. Omien kurssieni päätteeksi olenkin edennyt tehtäviin, joissa en enää toivo kirjaintarkan transkription kirjoittamista, vaan pyydän vastauksia sisältökysymyksiin: tekstiä pitää osata lukea, mutta nimenomaan löytäen olennaisimmat asiat. Tällöin yksittäiset sanat eivät enää jumiuta tulkintaa, mikäli aineistoa pystyy muutoin lukemaan riittävällä tarkkuudella.
Väitän, että vanhojen käsialojen tulkitsemisen ja laajemmin paleografian taitoja tullaan tarvitsemaan jatkossakin. Mutta miksi, kun hiljalleen esimerkiksi Kansallisarkistonkin aineistoihin laajenee automaattinen tekstintunnistus ja koneluenta Transkribus-yhteistyön myötä? Olenko opettajana ja tutkijana neliraajajarrutuksessa vastustamassa vääjäämätöntä kehitystä? Mielestäni en, koska pidän vanhojen tekstien tulkinnan taitoa historia-alan ammattilaisen perustaitona, josta tulee tuntea ammattiylpeyttä. Kaikkien miljoonien ihmisten, jotka hyödyntävät tekoälyä ei tarvitse tuntea syvällisesti sen toimintaperiaatteita algoritmeineen ja laskentatehoineen. Samoin kattolamppua käyttääkseen ei tarvitse olla sähköasentaja. Sen sijaan tekoälyohjelmoijan olisi syytä osata koodata, samoin sähköasentajan olla ammattiinsa kouluttautunut. Vastaavasti koen, että vaikka suuren historiasta kiinnostuneen massan kannattaa lähestyä menneisyyttä kustannustehokkaasti ja saavutettavasti automaattisen tekstintunnistuksen avulla tuntematta käsialoja sen tarkemmin, on historian ammattilaisten kuitenkin syytä kouluttautua paleografian perustaitoihin ja harjoittaa itseään vanhojen aineistojen itsenäisessä tulkinnassa.
Tekoälyn hyödyistä mutta myös sen virheistä ja vaaroista käytävä keskustelu on vasta alullaan. Historia-alalla juuri akateemiset tutkijat ja arkistoalan ammattilaiset toimivat portinvartijoina, mikäli vanhojen aineistojen koneellisessa tulkinnassa syntyy ongelmia. Jos ammatti-ihminen ei osaa tarvittaessa korjata koneen virheitä, niin kuka sitten. Vain inhimillisen pääoman myötä valta pysyy viime kädessä ihmisellä, ei koneella. On ilmiselvää, että tutkijoiden kannattaa hyödyntää koneluentaa, koska niin voidaan käydä tehokkaasti läpi isoja aineistomassoja. Silti vähänkään laadullisemmat tutkimusaiheet vaativat myös aineistoyksityiskohtien lähempää tarkastelua, jolloin on syytä pystyä silmäilemään myös alkuperäisaineistoja. Sanatarkat ilmaisut on tulisi aina tarkastaa alkuperäislähteestä koneluennan tuottamien mahdollisten virhetulkintojen välttämiseksi.
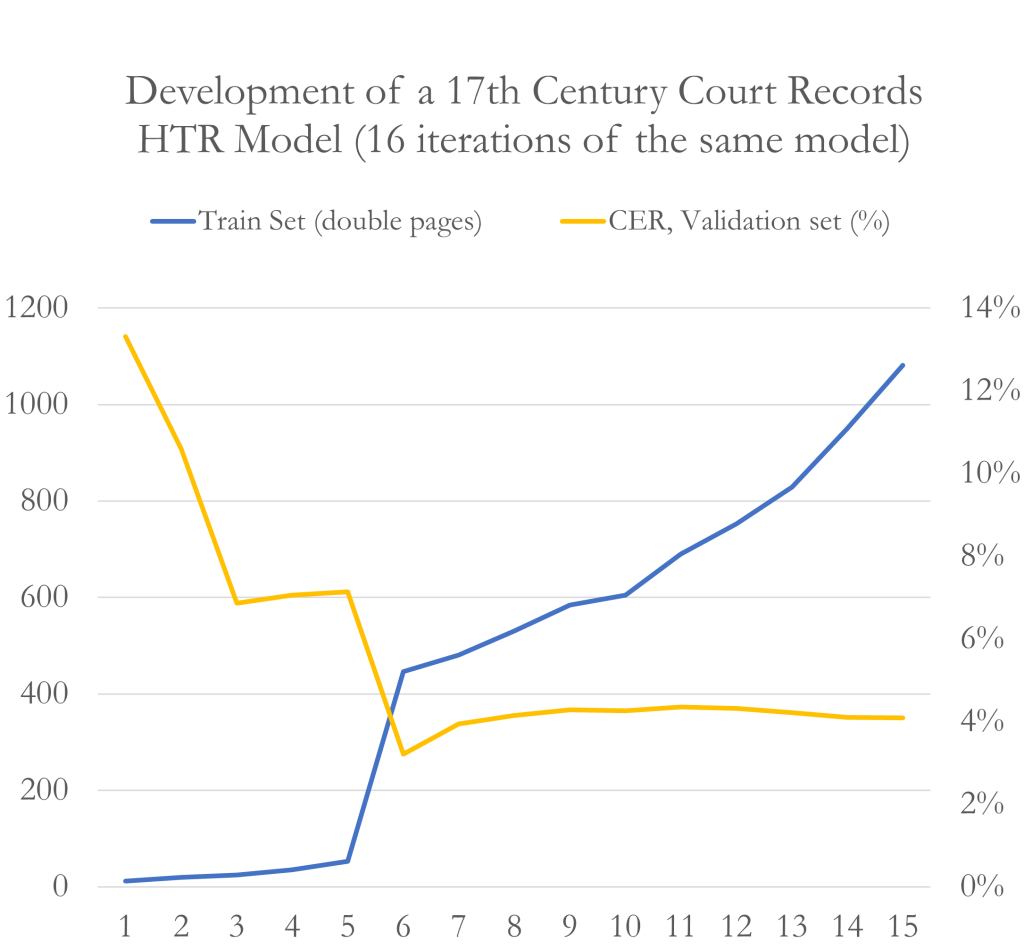
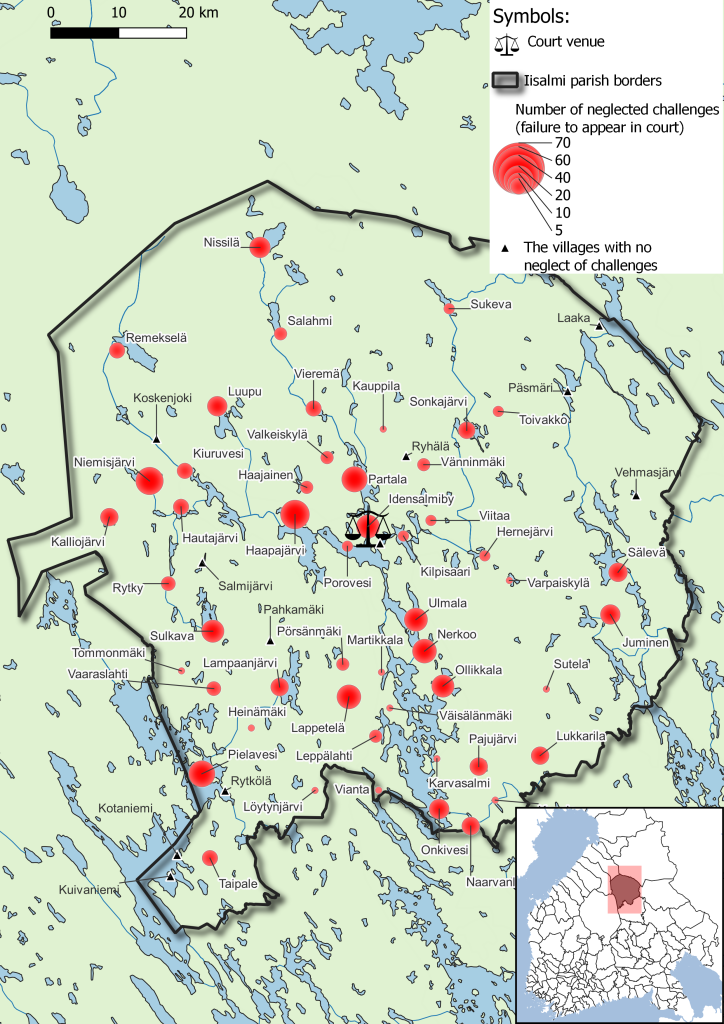
Olen parhaillaan tutkijana Ruotsin 1600-luvun kaupunginkirjureita ja heidän laatimiaan tuomiokirjoja analysoivassa hankkeessa. Tutkimuksessa hyödynnetään myös koneluentaa, mutta koska hankkeemme on kiinnostunut nimenomaan kaupunginkirjurien erilaisista käsialoista ja persoonallisesta kielenkäytöstä luemme isojakin aineistomassoja lävitse omin silmin. Koneen tuottama transkriptio ei nimittäin paljasta esimerkiksi niitä kohtia, joissa käsiala vaihtuu yllättäen kesken tuomiokirjaniteen. Käytännössä lähes kaikissa Ruotsin kaupungeissa on tuomiokirjoja laatineita (apu)käsiä ollut enemmän kuin virassa olleita kaupunginkirjureita. Koneluento ei myöskään osoita kirjurin tekemiä pieniä mutta olennaisia merkintöjä, esimerkiksi hänen korostettuaan tiettyä sanaa muuta teksti paksummilla kirjaimilla, alleviivauksin tai koristeellisemmin sulkakynän vedoin. Sen sijaan tällaiset tehokeinot on helppo havaita ihmissilmällä.

Kokemukseni perusteella alkuperäisaineistojen lukeminen omin silmin ja tulkinnoin on ylipäätään hyvä tapa syventyä tutkittavaan aikakauteen, käsinkosketeltavalla ja inhimillisellä tasolla. Koska historiatiede tutkii menneisyyttä viime kädessä tekstien avulla, on ainakin joskus hyvä vilkaista alkuperäisaineistojen ilmettä ja miettiä niitä ihmisiä, jotka ovat laatineet aineiston satoja vuosia aiemmin persoonallisella tyylillään. Työergonomisesti järkevän etä- ja koneluennan vaarana on se, että tutkija etääntyy menneisyyden artefakteista, joten ainakin välillä on hyvä harjoittaa myös aineiston itsenäistä lähiluentaa. Siksi vanhojen käsialojen tulkinta on perustaito, joka on hyvä löytyä takataskusta vähintään tarvittaessa. Kannustan siis jokaista varhaismodernista ajasta kiinnostunutta uusien teknologioiden suomien mahdollisuuksien ohessa opettelemaan ja aika ajoin ylläpitämään henkilökohtaisia paleografian taitoja. Se tekee tutkimuksesta myös inhimillisempää!
FM Petteri Impola on väitöskirja- ja projektitutkija Jyväskylän yliopiston historian ja etnologian laitoksella. Hän tutkii parhaillaan kaupunginkirjureita 1600-luvun Ruotsissa Koneen Säätiön rahoittamassa hankkeessa Kielen asiantuntijat, menneisyyden tallentajat: Kaupunginkirjureiden ammattikunta, toimijuus ja kielenkäyttö Ruotsin valtakunnassa varhaismodernina aikana 1614–1714 (Kaski).